I’ve been observing a growing shift toward a more Closed Web. At the core of this change appear to be fundamental shifts in the value exchanges between web publishers and technology platforms.
Given that Instapaper is a product that relies on the Open Web, I’ve been thinking a lot about this shift, the underlying causes, and the impact to Instapaper & similar Open Web products.
1. Shift to Subscription Models
Over the past decade, the media industry has heavily shifted the way they monetize content from ad-supported models toward subscriptions. The NYTimes paved the way here with their leaky paywall, which introduced some friction to customers, but largely left the content available and accessible on the open web.
In the past 10 years, NYTimes grew their digital-only subscribers from 800k to 6.5M for their news product, and reported over 10M digital subscriptions across all their products, and surpassing $1B in revenue from digital subscriptions in ’23.
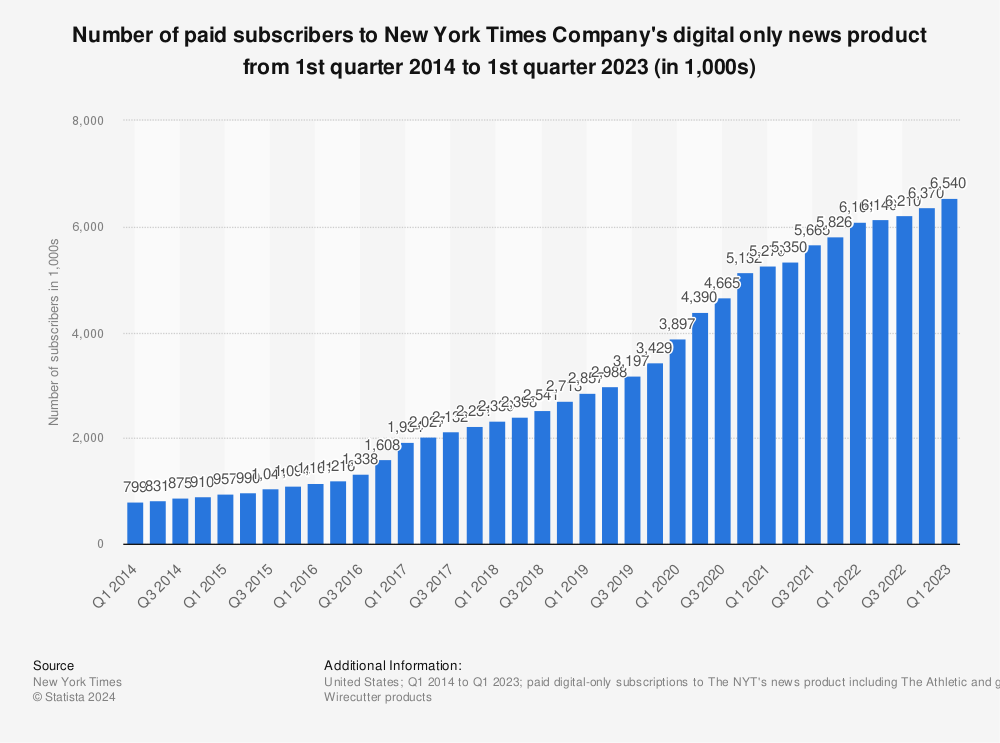
On the coattails of the NYTimes success, many of the large media companies have followed suit. Additionally, entire tech platforms have been built on the back of the shift to subscriptions including companies like Substack and Patreon.
Subscription-based content marks a fundamental shift from the value model that defined the early days of the Open Web. Back then, monetization was largely ad-driven; the goal was to attract as much traffic as possible, maximize links, and minimize friction for visitors.
In today’s more Closed Web, it’s nearly impossible to browse the web without a barrage of paywalls with CTAs to enter your email and subscribe.
2. Rise of Large Language Models
In late 2022, OpenAI launched ChatGPT, marking the beginning of the Large Language Model era. The biggest challenge in Machine Learning is always around collecting large amounts of high-quality data for training, and OpenAI did something fairly novel. They used the Transformer framework published by Google, trained it on web-scale data, and launched it as ChatGPT.
Unlike earlier web-scale platforms such as Google, ChatGPT emerged as an AI presented as all-knowing, leveraging knowledge sourced from the Open Web without linking and driving traffic to original sources. In doing so, ChatGPT disrupted the established value exchange that has long underpinned the Open Web.
And web publishers are pissed. In late ’23, NYTimes launched a lawsuit around OpenAI and Microsoft’s use of their copyrighted data in training these models claiming billions of dollars in damages.
Last year Apple announced their AI offering. As part of the announcement, Apple shared that the training data was collected from the Open Web using Applebot (previously only used by Siri and Spotlight). This came as an unexpected surprise to Apple bloggers who are sometimes critical, but generally extremely loyal to Apple. From Federico Viticci at Macstories:
Everything was cool until they mentioned how – surprise! – Applebot had already indexed web content to train their model without publishers’ consent, who can only opt out now. (This was also confirmed by Apple executives elsewhere.)
As a creator and website owner, I guess that these things will never sit right with me. Why should we accept that certain data sets require a licensing fee but anything that is found “on the open web” can be mindlessly scraped, parsed, and regurgitated by an AI? Web publishers (and especially indie web publishers these days, who cannot afford lawsuits or hiring law firms to strike expensive deals) deserve better.
Increasingly I’ve noticed that LLMs like ChatGPT and Gemini from Google are providing LLM responses while also citing sources, and I’m hopeful that this will provide a balance between the convenience offered to end users and the value exchange publishers expect.
3. Bot Detection and Blocking
There’s been an increasing effort around bot detection and blocking traffic from “bots”. There are likely a few factors converging here, but I suspect an important one is the use of open web data to train large language models.
In late ’23 and early ’24 , I received a flood of reports that Instapaper was being blocked by the NYTimes. After digging in, I noticed NYTimes started using DataDome to prevent bots from accessing their website. DataDome appears to be a relatively small company that promises to “Detect and mitigate bot & online fraud attacks with unparalleled accuracy and zero compromise.” The timing seems to line up with the NYTimes OpenAI lawsuit.
It goes without stating that the NYTimes should serve traffic (or block traffic) to whomever they see fit. That said, I’d like to think that the intention of implementing bot detection is not to block their subscribers from saving articles to a service like Instapaper1.
These bot-blocking companies really throw the Open Web baby out with the bot traffic. They will often offer a Verified Bot Program whose requirements are opaque. For example, I reached out to DataDome customer support to inquire about their Verified Bot Program. I was told that Instapaper needed a DataDome customer to ask DataDome to allow Instapaper otherwise we’d continue to be blocked from all websites they support. 2
In addition to the platform approach to blocking “bot” traffic, smaller independent bloggers are putting together posts about blocking AI crawlers:
- Go ahead and block AI web crawlers
- Blocking Bots with Nginx
- How We’re Trying to Protect MacStories from AI Bots and Web Crawlers – And How You Can, Too
Of course, these techniques require that companies adhere to robots.txt and/or provide an identifiable User-Agent. From The Verge:
In theory, Perplexity’s chatbot shouldn’t be able to summarize WIRED articles because our engineers have blocked its crawler via our robots.txt file since earlier this year. This file instructs web crawlers on which parts of the site to avoid, and Perplexity claims to respect the robots.txt standard. WIRED’s analysis found that in practice, though, prompting the chatbot with the headline of a WIRED article or a question based on one will usually produce a summary appearing to recapitulate the article in detail.
While I understand and appreciate the concern from the publishers3, I am concerned we’re moving toward a Web where access is deny-by-default instead of allow-by-default. Further, I’m concerned about the impact that will have on the accessibility, innovation, and openness of the web.
4. Closed APIs
A hallmark of the Web 2.0 era was open APIs. There was almost an implicit expectation that any Web 2.0 service would have an open API where application developers could build new programs/services/bots, and users could access their content outside the confines of the walled-garden nature of the Web 2.0 services.
More recently, there’s been a trend toward closed APIs that has been at least partially inspired by the rise of Large Language Models.
In February ’23, Twitter started the trend of closing their API to a more limited, paid-only version. At the time it seemed that the motivation was to shutdown the ecosystem of third-party Twitter Reader applications that existed since Twitter’s inception, but shortly after Elon sent some tweets to suggest that it was at least partly motivated to limit companies use of tweets as training data:
They trained illegally using Twitter data. Lawsuit time.
— Elon Musk (@elonmusk) April 19, 2023
I’m open to ideas, but ripping off the Twitter database, demonetizing it (removing ads) and then selling our data to others isn’t a winning solution
— Elon Musk (@elonmusk) April 19, 2023
Shortly afterward in April ’23, Reddit announced a similar change to a closed, paid-only version of the API. A few months later, Reddit CEO confirmed this was inspired by Twitter’s shuttering of third-party app ecosystem:
Huffman said he saw Musk’s handling of Twitter, which he purchased last year, as an example for Reddit to follow.
“Long story short, my takeaway from Twitter and Elon at Twitter is reaffirming that we can build a really good business in this space at our scale,” Huffman said.
“Now, they’ve taken the dramatic road,” he added, “and I guess I can’t sit here and say that we’re not either, but I think there’s a lot of opportunity here.”
But it’s also clear that a major motivation for Reddit was limiting access to companies like OpenAI from using Reddit comments as training data:
“The Reddit corpus of data is really valuable,” Steve Huffman, founder and chief executive of Reddit, said in an interview. “But we don’t need to give all of that value to some of the largest companies in the world for free.”
Since then Reddit has struck content licensing deals with both Google ($60M) and OpenAI (undisclosed).
With these more limited, paid-only APIs, we are likely to see less innovation and competition from companies building on other platforms. After seeing what happened with products like Tweetbot and Apollo, I’d personally be hesitant to build on anyone else’s platform ever again.
5. Slowing Growth
In 30 years the number of users on the web went from 15 million to over 5 billion today. It has been a period of remarkable growth and adoption. In the wake of that growth, some of the largest companies of all-time were built like Amazon, Google, and Facebook, and countless others capitalized on that growth and adoption.
However, as the number of Internet users surpasses 68% of the total population the opportunities for free growth are shrinking. The average growth rate over the past 5 years has been 6%, versus 11% in the prior 5 years.
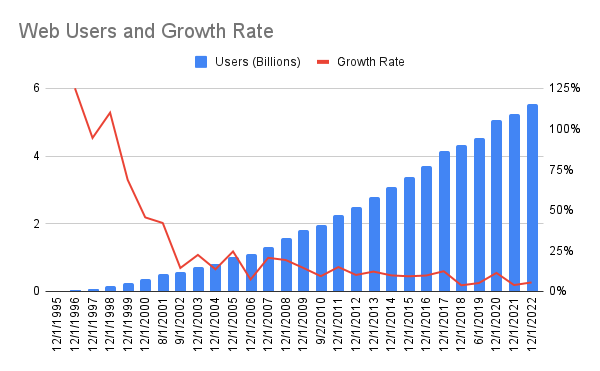
It’s impossible to correlate the overall macro trend with the shifts we are seeing on the web, but I hypothesize there’s a relationship between the web’s growth rate and the trend toward a more closed web.
It seems more likely that with double-digit yearly growth, people and companies are more open to offering their products with low friction to drive higher usage and adoption. As growth slows, people and companies are more focused on capturing value from the existing users.
Impact on Instapaper & Open Web Products
Instapaper enables users to save links for later reading, relying on the Open Web to display links and their content effectively. Closed Web trends like the rise of paywalls, bot-blocking measures, and restricted APIs pose a significant threat to Instapaper and similar services that depend on an Open Web.
Recent analysis of parsing failures on Instapaper revealed that ~75% stemmed from the platform being unable to access content. While paywalls were a contributing factor, bot blockers increasingly caused issues, returning 403 Forbidden errors that even blocked access to basic metadata like titles, descriptions, and thumbnails.
This shift has been a personal source of anxiety, raising concerns about Instapaper’s long-term viability if these trends persist.
I’m happy to share that we’ve largely addressed this challenge and will be rolling out an update to Instapaper in the coming weeks. Our solution respects paywalled content while ensuring subscribers can access their content when saved to Instapaper. More details will be shared when the update launches, and I plan to write a follow-up here afterwards.
That said, the broader trend toward a more Closed Web remains deeply concerning. These barriers threaten the broader ecosystem of Open Web innovation. Without open access, it may become difficult to build new link-based products, thereby stifling innovation on the web.
-
Instapaper only accesses content when a user saves it, and does not systematically scrape websites for other purposes.
Additionally, Instapaper is very small scale relative to NYTimes’ digital subscription base, and the majority of people saving articles are NYTimes subscribers. ↩ -
If you, dear reader, are a customer or employee of DataDome please do get in touch with me directly. ↩
-
And again, it’s their right to block whomever. ↩