Today Instapaper launched Summaries, which is a feature I’ve wanted to build for a long time. Summaries help readers both understand an article before reading it, and help them recall the details of previously read articles.
Building summarization features has become a whole lot easier with new tools and APIs, and this post will outline the technical details on how Instapaper generates its summaries.
Instapaper Summaries are generated using a multi-level summarization technique, where the summary is generated in two steps:
- Extractive Summarization: Most relevant sentences extracted from the text.
- Abstractive Summarization: Generate an independent summary from the extracted sentences.
Below we’ll dive into the technical details on each step and how it comes together in the product…
Extractive Summarization
Extractive Summarization is a technique to create a summary by extracting portions of the provided text.
For instance, Instapaper Summaries use TextRank for Sentence Extraction, which is based on the premise that the most relevant sentences have the most similarity to other sentences in the document. The algorithm identifies the most relevant sentences by constructing a graph where every node is a sentence, and sentences are connected by similarity based on overlapping words.
Instapaper uses an open source library to build the graph using the TextRank algorithm, grabs the top 15 sentences (or fewer when fewer are returned), and then sorts them in the order they appear in the text. In the application code:
def key_sentences(text, num_sentences=15):
scored_sentences = textrank(text)
# Create dictionary with score and index
index_scored_sentences = [{'sentence': s[0], 'score': s[1], 'index': i} for i, s in enumerate(scored_sentences)]
# Sort by score and grab top N
index_scored_sentences.sort(key=lambda d: d['score'], reverse=True)
top_scored_sentences = index_scored_sentences[:num_sentences]
# Sort again by the original order/index and return only sentences
top_scored_sentences.sort(key=lambda d: d['index'])
return [d['sentence'] for d in top_scored_sentences]
In testing I often used Eugene Wei’s Status-as-a-Service blog post, which is both an excellent read, and an extremely long read. It clocks in at almost 20k words, 550 sentences, and would take the average reader over an hour to read.
Using TextRank we’ll extract the most relevant sentences from Status-as-a-Service. The table below includes the top 15 most relevant sentences in the article, and the position of each sentence in the article. If you look at each sentence’s position you’ll notice that, while not perfectly uniform, the highly ranked sentences are well distributed throughout the article.
| Sentence | Position in Article |
|---|---|
| A social network like Facebook allows me to reach lots of people I would otherwise have a harder time tracking down, and that is useful. |
7% |
| So, to answer an earlier question about how a new social network takes hold, let’s’ add this: a new Status as a Service business must devise some proof of work that depends on some actual skill to differentiate among users. |
19% |
| If I were an investor or even an employee, I might have something like a representative basket of content that I’d post from various test accounts on different social media networks just to track social capital interest rates and liquidity among the various services. |
23% |
| Otherwise a form of social capital inequality sets in, and in the virtual world, where exit costs are much lower than in the real world, new users can easily leave for a new network where their work is more properly rewarded and where status mobility is higher. |
26% |
| The same way many social networks track keystone metrics like time to X followers, they should track the ROI on posts for new users. |
27% |
| Maintenance of existing social capital stores is often a more efficient use of time than fighting to earn more on a new social network given the ease of just earning interest on your sizeable status reserves. |
41% |
| This bottom right quadrant is home to some businesses with over a billion users, but in minimizing social capital and competing purely on utility-derived network effects, this tends to be a brutally competitive battleground where even the slimmest moat is fought for with blood and sweat, especially in the digital world where useful features are trivial to copy. |
49% |
| In fact, it’s usually the most high status or desirable people who leave first, the evaporative cooling effect of social networks. |
59% |
| As with aggregate follower counts and likes, the Best Friends list was a mechanism for people to accumulate a very specific form of social capital. |
66% |
| Still, given the precarious nature of status, and given the existence of Instagram which has always been a more unabashed social capital accumulation service, it’s not a bad strategy for Snapchat to push out towards increased utility in messaging instead. |
69% |
| One way to combat this, which the largest social networks tend to do better than others, is add new forms of proof of work which effectively create a new reserve of potential social capital for users to chase. |
70% |
| Engagement goals may drive them towards building services that are optimized as social capital games, but they themselves are hardly in need of more status, except of a type they won’t find on their own networks. |
79% |
| It’s strange to think that social networks like Twitter and Facebook once allowed users to just wholesale export their graphs to other networks since it allowed competing networks to jumpstart their social capital assets in a massive way, but that only goes to show how even some of the largest social networks at the time underestimated the massive value of their social capital assets. |
88% |
| He accumulated millions of followers on Instagram in large part by taking other people’s jokes from Twitter and other social networks and then posting them as his own on Instagram. |
89% |
| Twitter is another social network where people tend to bring interesting content in the hopes of amassing more followers and likes. |
92% |
Leveraging this technique we’ve been able to generate an extractive summary that reduces the article by 98% to 550 words.
If you’ve read the post previously, I’m sure the above sentences will jog your memory. In addition to being a great tool for initially evaluating an article, it’s a great way to recall an article for the key points and easily jump between them.
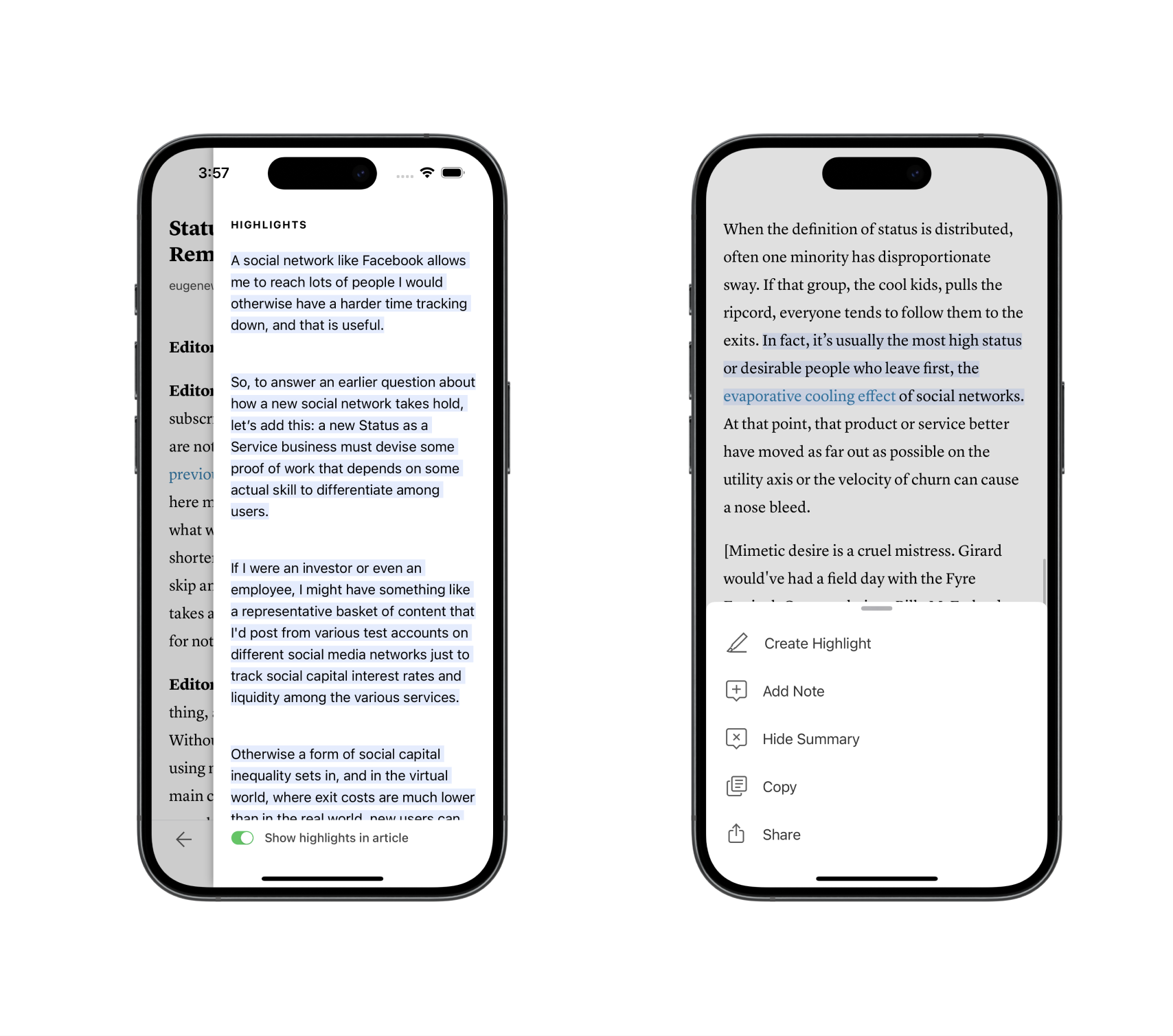
Extractive Summarization Performance
When building Instapaper Summaries, performance was a major consideration, and each component of the summarization process had performance evaluations around time, cost, and quality.
TextRank Sentence Extraction is a deterministic graph-based ranking algorithm, and its performance is directly correlated with the amount of text provided. Below is a table containing a selection of articles, the number of sentences in each article, and the time it took TextRank to generate the extractive summary.
| Article | Sentences | Est. Read Time | Time |
|---|---|---|---|
| The Mystery of White Rural Rage | 33 | 5 min | .06s |
| Why Substack is at a crossroads | 146 | 15 min | .4s |
| The Pain Hustlers | 325 | 35 min | 1.5s |
| Status as a Service | 547 | 82 min | 7.3s |
Graphing a sample of 1,000 articles from Instapaper, we can see the majority of articles have less than 400 sentences, and those mostly complete within a second:
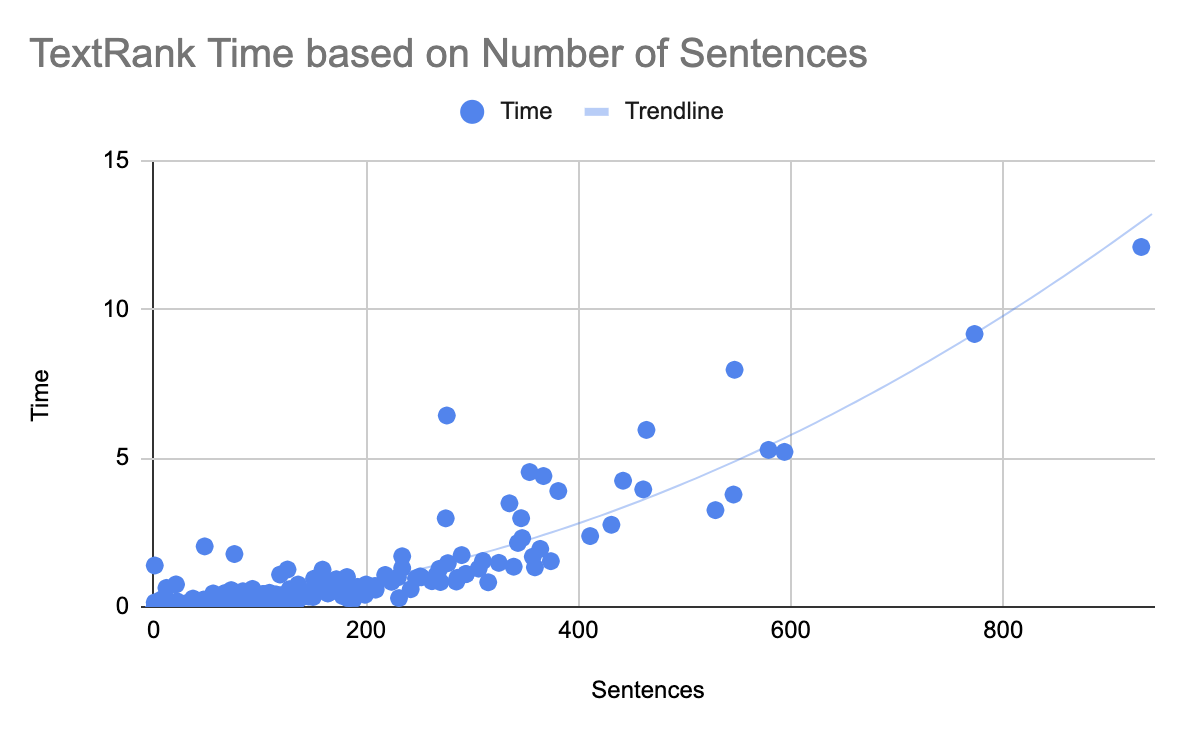
Below are the mean, median, and P95 for the 1,000 articles in the dataset evaluated:
| Stat | Sentences | Est. Reading Time | Time |
|---|---|---|---|
| Mean | 63 | 8 min | .25s |
| Median | 36 | 5 min | .05s |
| P95 | 234 | 26 min | 1.01s |
While the results are effective and create the right product experience, this call is expensive for longer articles.
In order to prevent server-side performance issues, I rely on a few factors:
- TextRank Sentence Extraction runs on compute-optimized machines that can withstand longer running tasks (i.e. not our API/web servers).
- Sentence extraction for large articles is done asynchronously, and the results are stored to prevent recomputing them.
- There is caching in place for all sentence extraction.
- Very few articles saved to Instapaper are more than 30 minute reads.
Abstractive Summarization
I evaluated a few abstract summary models including pegasus-xsum, t5, ChatGPT-3.5 Turbo, and ChatGPT-4 to generate abstract summaries of the articles. At this stage, the model evaluation was done mostly on the quality of the response and ignoring other factors like time and cost.
Based on the results from a small sample of articles, it’s clear that ChatGPT is the winner here. Given similar quality and less cost, we opted to use ChatGPT-3.5 Turbo instead of ChatGPT-4. Notably absent from the evaluation were other LLMs like Llama from Meta and Claude from Anthropic. Once I found that ChatGPT generated great summaries, I stopped evaluating additional models.
Long-term, I would like to bring the abstract summary closer to Instapaper’s infrastructure, especially given we can likely tune a model only focused on summarization that can potentially be smaller and faster than more general purpose LLMs.
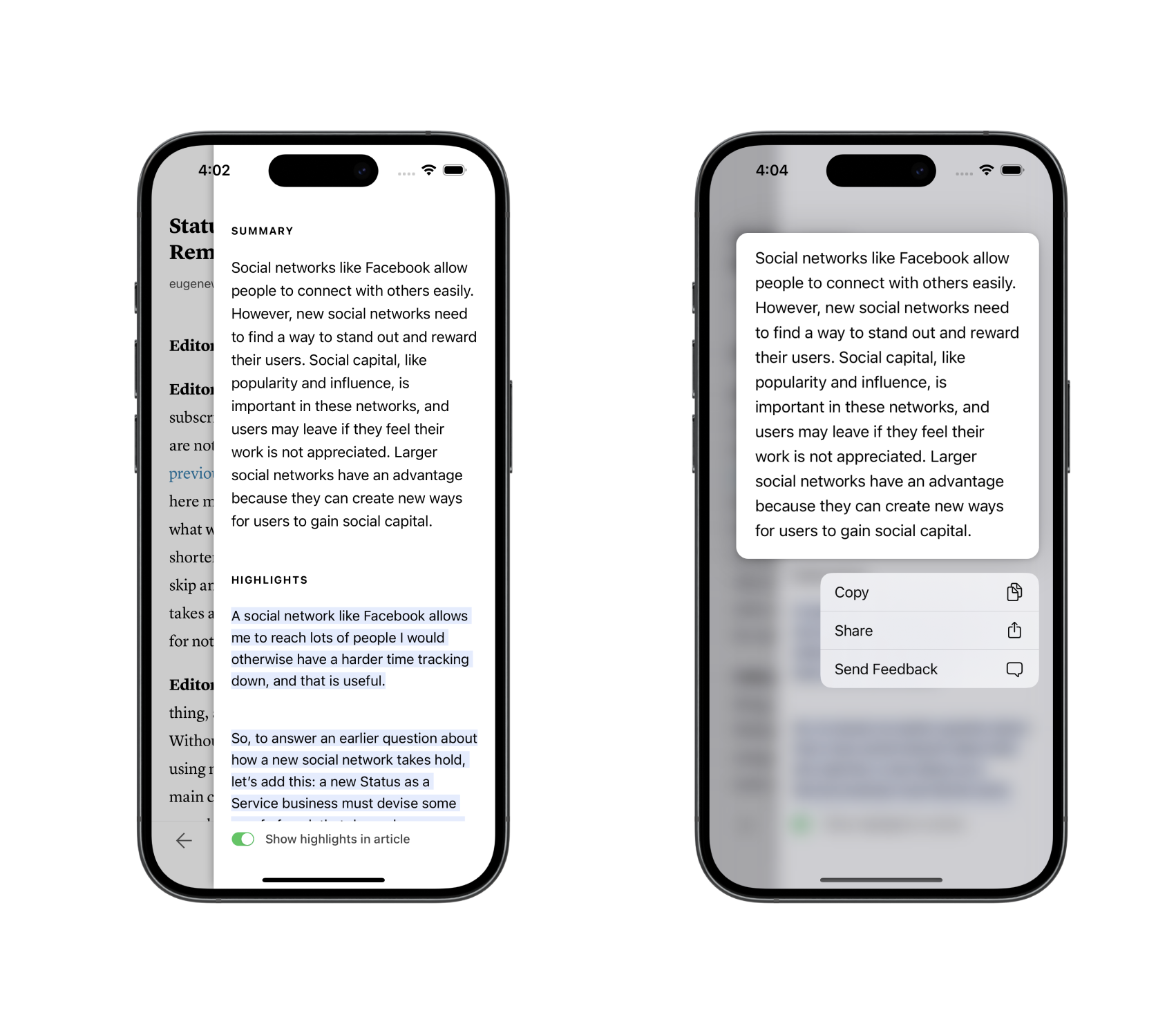 In the product, the abstract summary is shown above the summary highlights. Long press on the abstract summary provides the reader with some options.
In the product, the abstract summary is shown above the summary highlights. Long press on the abstract summary provides the reader with some options.
Using Status-as-a-Service against ChatGPT, there’s an issue with the size of the text provided. Here’s the response from the Completions API:
This model’s maximum context length is 16385 tokens. However, your messages resulted in 23607 tokens. Please reduce the length of the messages.
This seems to be a fairly common problem, and I quickly came across How to send long articles for summarization? from the OpenAI community forums. There are two solutions recommended in the thread:
- Sub-Summaries: Chunk the text into smaller parts. Summarize each part with ChatGPT. Combine the summaries, and then provide that to ChatGPT for a final summary.
- Refine: Chunk the text into smaller parts. Summarize the first part with ChatGPT. Combine the first summary with the second part, then summarize with ChatGPT. Repeat for all parts.
Using Status-as-a-Service, we’ll compare the above two approaches with Multi-Level Summarization, which provides the Extractive Summarization sentences to ChatGPT to generate the abstract summary.
Abstractive Summarization Performance
| Approach | Prompt Tokens | Cost | Time | Abstract Summary |
|---|---|---|---|---|
| Sub-Summaries | 23,646 | 1.21c | 5.83s | Social networks are like popularity contests where people try to gain more followers and likes to increase their status. Young people are often more active on social media because they have more free time and less social status than adults. While social media can be fun, it can also have negative effects on mental health and spread harmful information. It’s important for these platforms to find a balance between being enjoyable and keeping users safe. |
| Refine | 23,718 | 1.19c | 4.47s | Social networks like Facebook and Instagram are like games where people try to increase their popularity and status by accumulating likes, followers, and other forms of social capital. Young people often dominate social media because they have more time and less existing social capital compared to adults. However, social networks can also have negative effects on mental health and lead to feelings of anxiety and inadequacy. |
| Multi-Level Summarization | 643 | .063c | 1.62s | Social networks like Facebook and Instagram are places where people can connect with others and share things like jokes, photos, and ideas. These networks can be competitive because people want to gain more followers and likes, which can make them feel important. Sometimes, people might leave one social network for another if they think they can earn more status or attention there. |
Each approach comes with trade-offs against time, cost, and quality. Comparing Sub-Summaries with Refine:
- Time: Sub-Summaries require an additional API call to get the final summarized output, which results in +30% time to completed response.
- Cost: The cost difference is negligible (+1.6% for sub-summaries) because they use a similar amount of prompt tokens and output tokens, despite the additional API call.
- Quality: The output is very similar in terms of structure and content. That said, the last sentence about social media & mental health is not something actually discussed in the article other than a brief mention of societal impact of social networks.
Next we’ll compare Refine with Multi-Level Summarization:
- Time: Multi-Level Summarization requires a single API call to ChatGPT, which is 63% faster than Refine. However, it requires the upfront time to generate the sentences. Combining the total time for Multi-Level Summarization (8.92s), it’s 50% slower when the sentences also need to be extracted.
- Cost: Given Multi-Level Summarization uses a sample of highly ranked sentences to generate the summary, it uses significantly fewer prompt tokens (98% less), and as a result is 47% cheaper. There is some negligible compute cost to extract the sentences that are not included.
- Quality: Despite much less text input, ChatGPT seems to return a more on-topic and appropriate summary for multi-level summarization. The last sentence in particular more accurately captures the point of the article versus the other two approaches.
With longer articles, multi-level summaries can be conducted in less time and cheaper than alternative solutions. Additionally, there’s evidence to suggest that ChatGPT performs better when being provided with fewer, more highly relevant sentences versus the entire text.
For completeness, we also evaluated ChatGPT against shorter articles which fit within one API call. We found time difference negligible between approaches, cost for multi-level approach was 65% cheaper, and quality to be comparable. See below for abstract summaries for Why the Internet Isn’t Fun Anymore (50 sentences, 5 min read):
| Approach | Prompt Tokens | Cost | Time | Abstract Summary |
|---|---|---|---|---|
| Entire Text | 1,682 | .087c | 1.77s | The author discusses how social media platforms like Twitter, Instagram, and TikTok have changed over time. They explain that these platforms have become less fun, more hierarchical, and focused on self-promotion. The decline in these platforms has also affected the spread of news and content from outside sources. |
| Multi-Level Summarization | 515 | .031c | 1.57s | Recently, the social media platform X (formerly known as Twitter) has been filled with posts that aren’t very meaningful and keep repeating the same few topics. Users who pay to be verified by Elon Musk dominate the platform and often share right-wing opinions and false information. Social media used to be a place for conversation and connecting with others, but now it feels more like a broadcast station where one person talks to millions of followers. Additionally, people are spending less time on social media and less likely to click on links shared there. |
Based on the above, I chose Multi-Level Summarization as the best approach for all Instapaper summaries given the fewer API calls, lower cost, and optimizations made for sentence extraction in large articles.
Abstract Summary Internationalization
People from all over the world use Instapaper to read, and I wanted to ensure some basic support for internationalization in summaries. For Extractive Summarization, the summaries are generated using text directly in the article, and I did some testing to ensure that languages like Chinese and Japanese, which do not use a Latin-style period, worked reasonably well.
For the Abstract Summary powered by ChatGPT, I found that when prompted in English with non-English text, the response would be in English. I attempted some prompt engineering to ensure the responses were in the same language of the text and added “Respond in the language of the text.” to our prompt. I found that while this mostly worked, ChatGPT would occasionally revert to English when responding.
In order to ensure ChatGPT responds in the correct language, I integrated language detection to determine the language on the extracted sentences:
def language_code_for_text(text):
lang_probabilities = langdetect.detect_langs(text)
if not lang_probabilities:
return None
lang_probability = lang_probabilities[0]
return lang_probability.lang if lang_probability.prob >= 0.8 else None
In testing, I found a probability over 80% was a pretty reliable indicator of successful language detection, with most results returning over 95%. Performance-wise langdetect runs pretty reliably in 20-30ms regardless of the language or size of text.
If language detection fails, Instapaper falls back on the prompt engineering solution:
language = nlp.language_for_text(prompt) or 'the language of the text'
system_prompt = 'Respond in %s.' % language
In Summary…
For fun, I took a draft of this article, saved it to Instapaper, and generated a summary:
Instapaper has developed a way to generate summaries of articles using a two-step process. First, they create a summary by taking important parts of the text. Then, they use a tool called ChatGPT to generate a more general summary. This method is faster and cheaper than other methods they tried, and it works well for articles in different languages.
This was my first deeper foray into natural language processing, generative AI, and building features based on these new tools. A big reason I’ve been excited about Going Full-Time on Instapaper is exploring how to improve Instapaper with machine learning.
Summaries are a small baby step in that direction. It was a lot of fun exploring the different techniques for summarizing text, understanding the power of the new generative AI tools–and its limits, and I’m ultimately really happy with how the feature came out. If you have a chance to try Instapaper Summaries, I’d love to hear your feedback on Twitter1.
Thanks to Jon Parise, Linus Lee, and Ying Yang for providing feedback on drafts of this post. Also special thanks to Linus Lee who provided feedback on the technical approach throughout the implementation
-
Still calling it Twitter. ↩